
前言
某产品经理提出以下三个需求开发一个程序:
1. 每天自动从网上找到新闻
2. 自动整理新闻排版成一张图片
python有强大的网络爬虫能力,实现这样的功能还是很快的
准备工作
- 确定新闻信息源
找一个提供新闻的网站,这里我用的是 https://www.pmtown.com/archives/category/早报 这个网站,每天会更新一篇新闻。
- python安装依赖库
requests : 用来访问请求网站
bs4 : 用来从网站标签中提取数据
- 安装效果图
代码实现
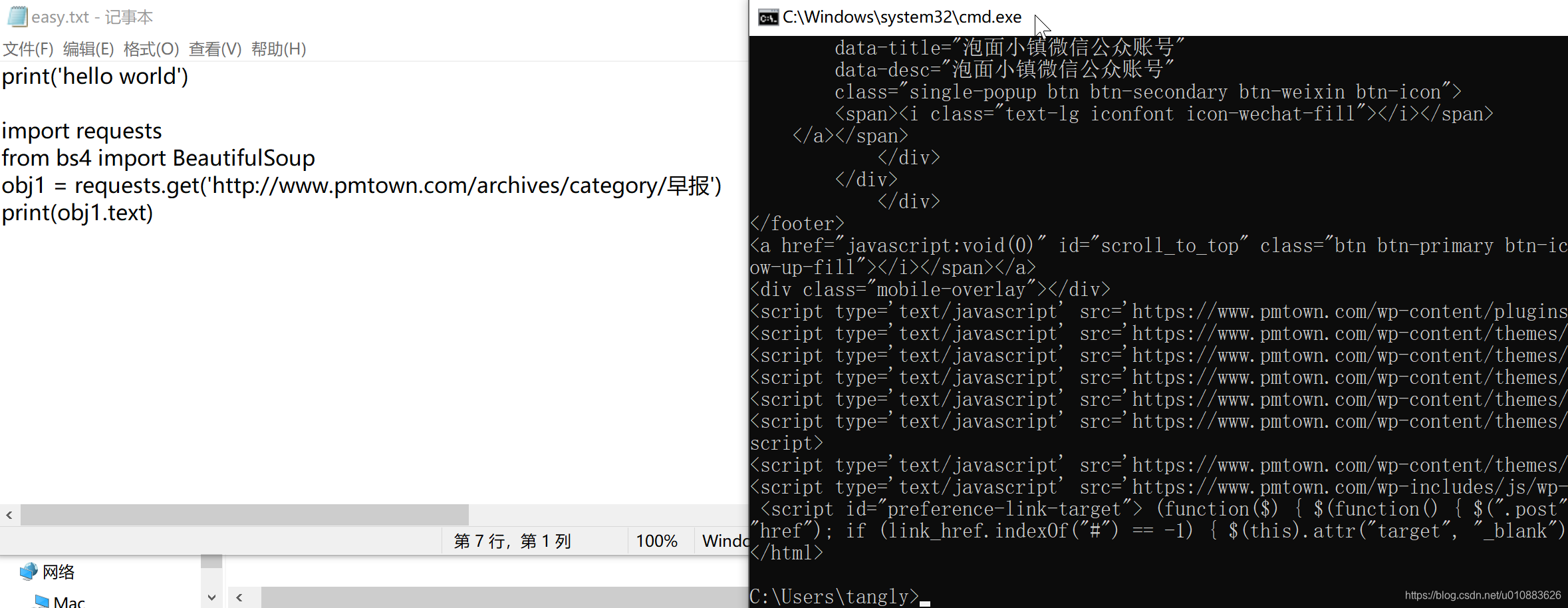
用request库抓取网页上的文本信息
在easy.txt中写入这几行代码:
import requests ;将requests库引入
from bs4 import BeautifulSoup ; 从 bs4 这个库中只引入BeatifulSoup这个对象
obj1 = requests.get('http://www.pmtown.com/archives/category/早报'); 用requests库的 get 方法请求网页,obj1是个临时变量
print(obj1.text) ; 打印请求到的网页内容保存文本,并执行代码;
执行效果
分析页面元素中所需的内容
对着最新的一条新闻,右键点击检查,浏览器中会弹出相应的标签文本;
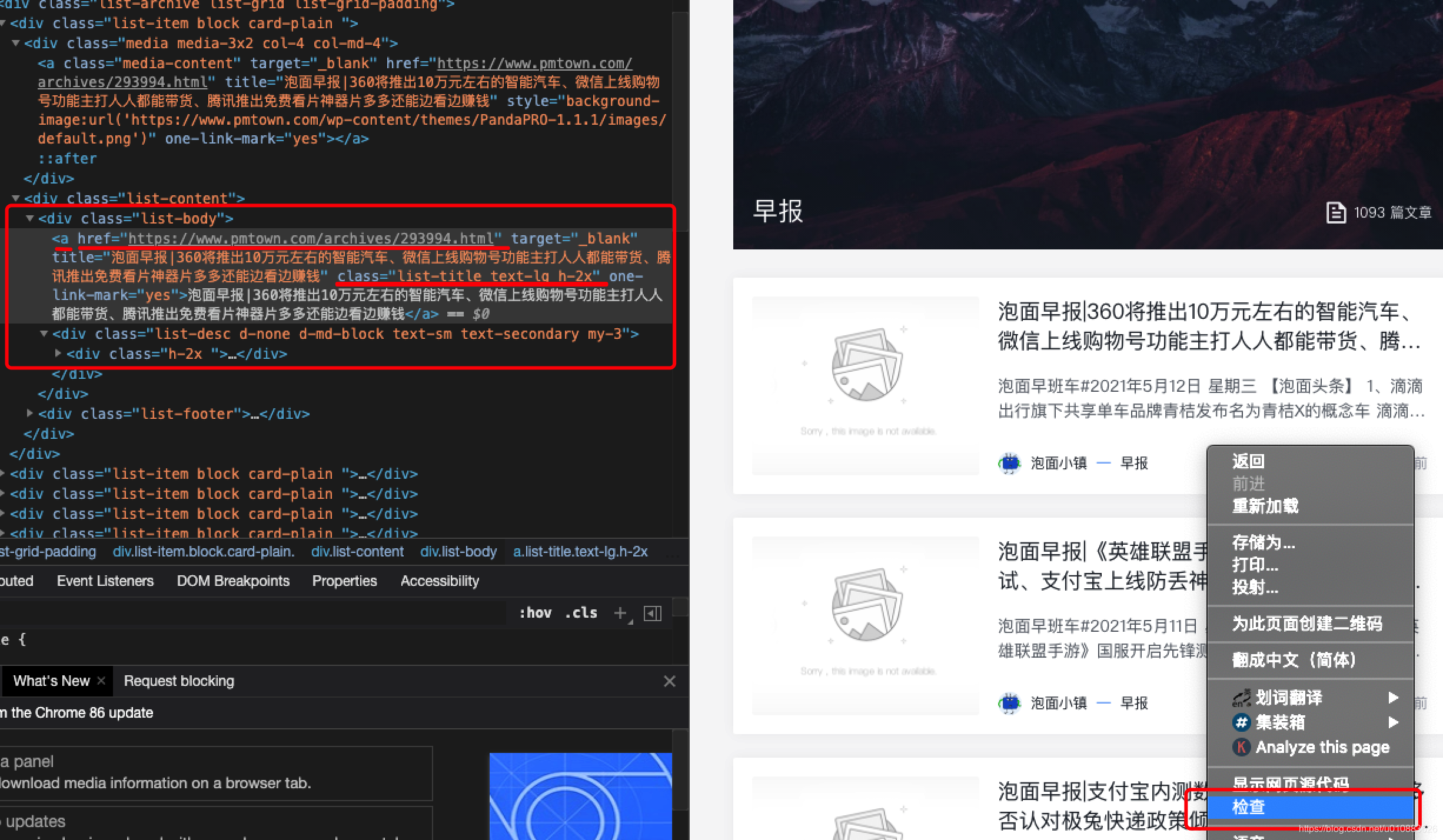
分析一下这部分网页的代码
1. 列表里是所有的新闻地址,按时间倒序排列,最新的在最上面;每天会有一条新的早报地址;
2. 他是一个 <a></a> 标签包裹的
3. 这个a标签中有一个class="list-title text-lg h-2x"
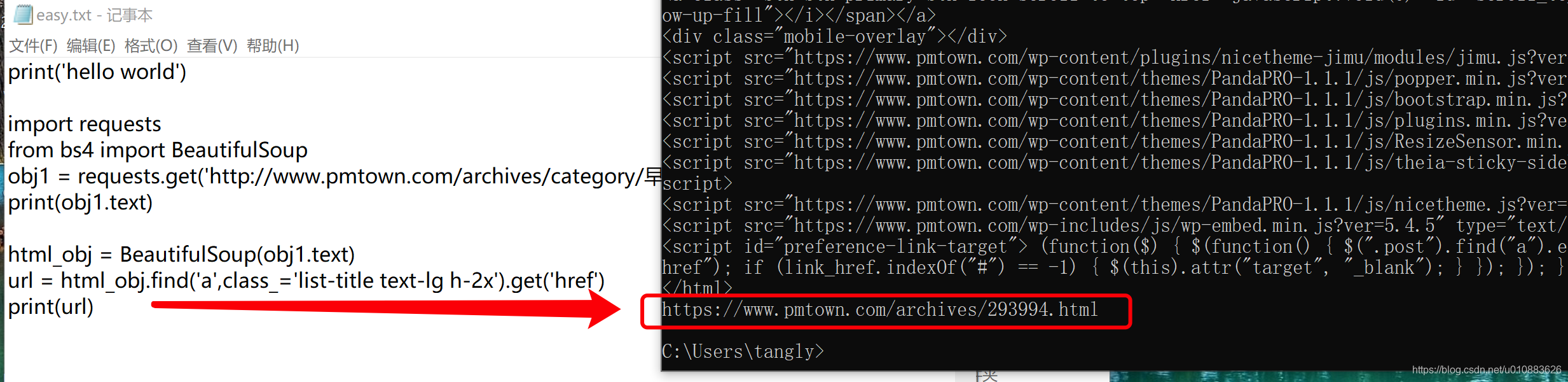
4. 路径在这段代码的href=""中 可以看到这条新闻的地址是 https://www.pmtown.com/archives/293994.html
编码实现查找页面元素
用以上的规律信息,我们可以定位到每天最新新闻的地址。代码如下:
html_obj = BeautifulSoup(obj1.text) 用BeautifuSoup包装网页文本,便于解析查找数据的功能
url = html_obj.find('a',class_='list-title text-lg h-2x').get('href') 查找指定a标签,该a标签中有一个class值为'list-title text-lg h-2x',找到后,获取该a标签中的href字段
print(url) 找到了就打印出来看看执行效果:
上一步,我们获取到了每天最新的新闻地址。接下来我们打开上面的地址详情页分析一下。
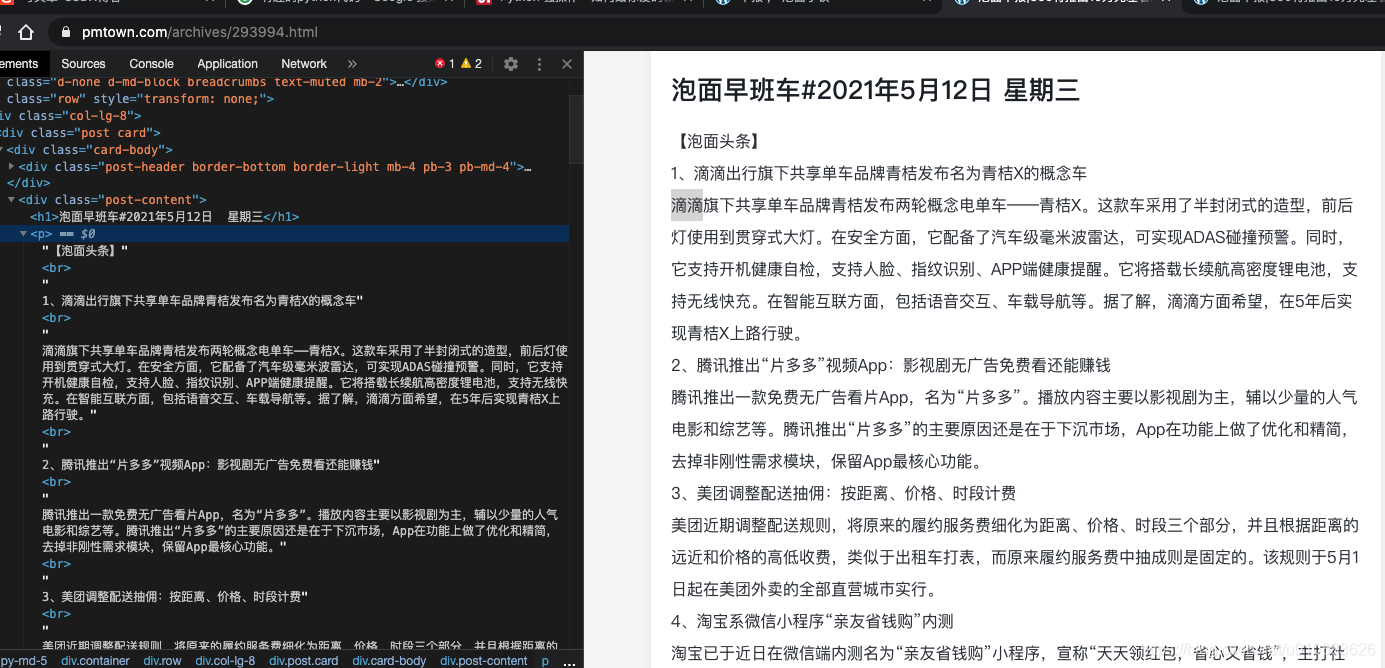
右键检查,分析网页代码规律:不难发现,这个代码的特点是:
1. 新闻信息和日期在<h1></h1>中包裹着
2. 新闻内容在<p></p>中包裹着
代码如下:
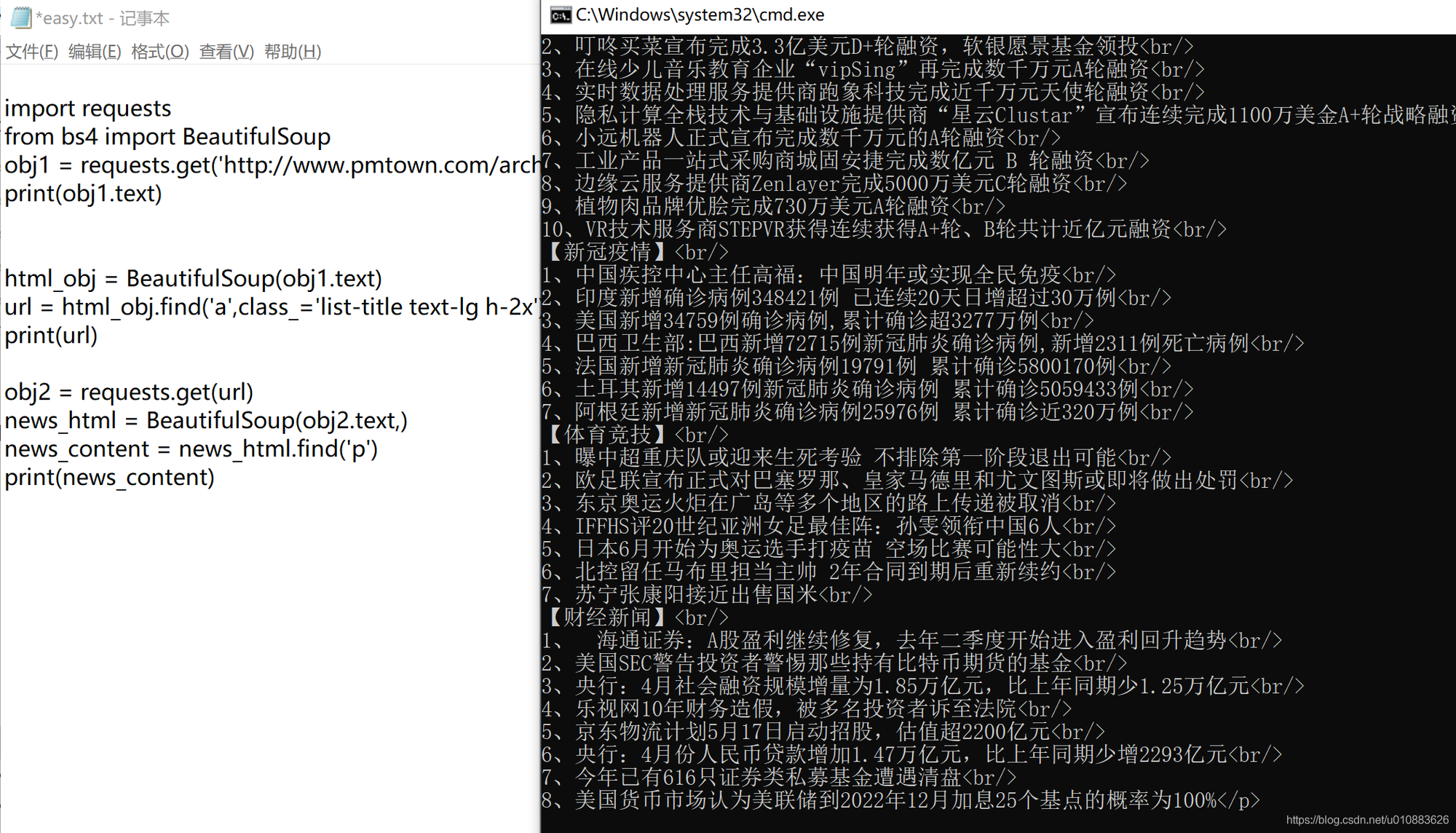
obj2 = requests.get(url) url是上一步获取的最新新闻的网址
news_html = BeautifulSoup(obj2.text) 用BeautifulSoup对象包装一下请求到的网站文本
news_content = news_html.find('p') 查找<p>标签
print(news_content) 找到了就打出来看看这段代码执行效果:将新闻信息提取出来,并打印在屏幕上。
总结
这里我们用到了python的request库以及BeautifulSoup库实现了网页信息的获取与查找。核心代码行数不超过20行。同样的方式我们还可以做更多事,例如获取天气、查询股票价格等等需要信息获取的需求。
Loading...





